
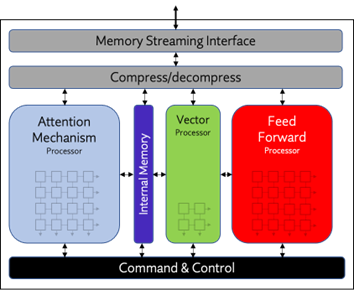
Origin Evolution offers unparalleled accuracy and predictable performance without requiring any hardware-specific optimizations or modifications to your trained model. Its patented packet-based execution architecture delivers single-core performance of up to 128 TFLOPS and maintains utilization rates of 70-90%. These metrics are measured on silicon while running typical AI workloads like Llama and YOLO. This outstanding performance and efficiency allow users to execute LLM, CNN, and other AI models with significantly lower power consumption compared to alternative solutions.
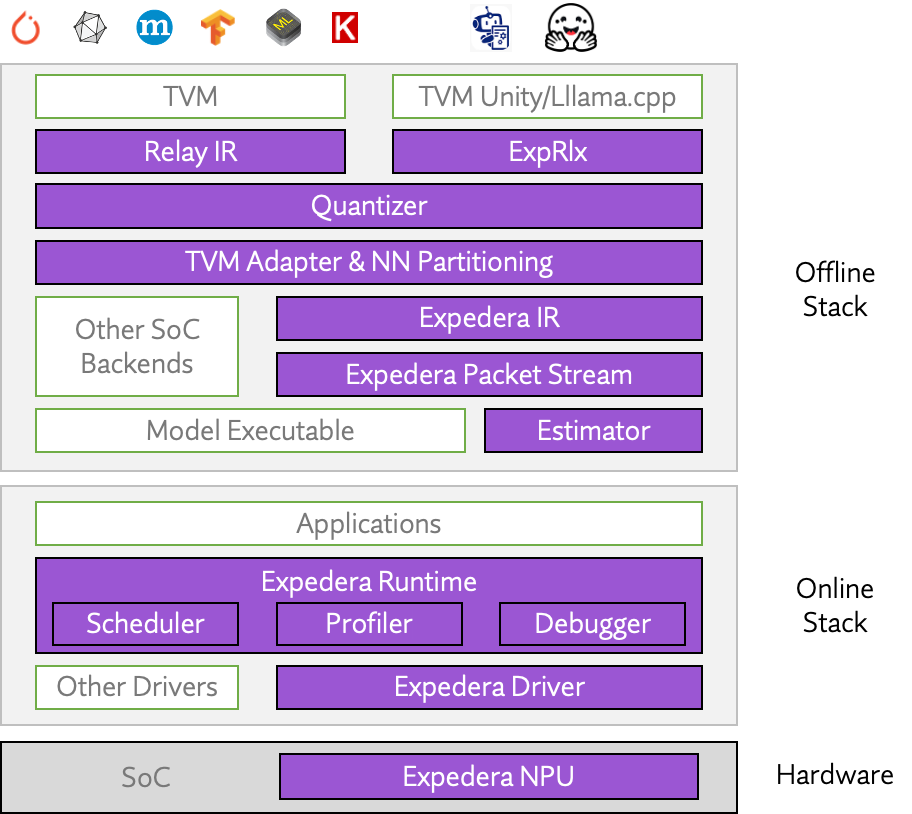
Expedera’s Origin Evolution IP platform includes a full TVM- and Relax-based software stack that enables developers to work efficiently as they deploy their networks on the target hardware—supporting popular frameworks such as HuggingFace, Llama.cpp, PyTorch, Onnx, TensorFlow, TVM, and others. Users can deploy their trained models as-is; no retraining or accuracy reductions required. The software stack automatically handles tasks such as packetization and debugging while providing user-friendly options such as mixed precision (integer and floating point) quantization—using your tools or ours—custom layer and network support, and multi-job APIs.

Origin E1
The Origin E1 processing cores are individually optimized for a subset of neural networks commonly used in home appliances, edge nodes, and other small consumer devices. The E1 LittleNPU supports always-sensing cameras found in smartphones, smart doorbells, and security cameras.




Origin E1
Origin E1 neural engines are optimized for networks commonly used in always-on applications in home appliances, smartphones, and edge nodes that require about 1 TOPS performance. The E1 LittleNPU processors are further streamlined, making them ideal for the most cost- and area-sensitive applications.

Origin Evolution for Automotive
Designed for performance-intensive automotive/ADAS applications, Origin Evolution for Automotive NPU IP cores excel at complex AI tasks, including computer vision, LLMs, warping, point cloud, grid sampling, image classification, and object detection. Single-core performance scales to 96 TFLOPS in a single core, with multi-core performance to PetaFLOPs.



