
There is a lot more to understanding the capabilities of an AI engine than TOPS per watt. A rather arbitrary measure of the number of operations of an engine per unit of power, this metric completely misses the point that a single operation on one engine may accomplish more useful work than a multitude of operations on another engine. In any case, TOPS/W is by no means the only specification a system architect or chip designer should use in determining the best AI engine for their unique application needs. Any experienced system designer will tell you that factors such as software stack, chip size/area requirements, fitness for specific neural networks, and others are often more important.
Still, TOPS/W is often one of the first performance benchmarks provided by NPU (Neural Processing Units) makers—including Expedera—and it can be useful if considered in the context of the underlying test conditions. Unfortunately, there is no standardized way of configuring the hardware or reporting benchmark results and this makes it challenging when comparing different NPUs.
Let’s explore how the underlying test conditions come into play when looking at TOPS/W benchmark data.
Frequency as a Variant in TOPS/W
The TOPS metric is defined according to the formula: TOPS = MACs * Frequency * 2. Let’s start with the frequency portion of the equation. There is no ‘best’ or ‘most correct’ frequency that an NPU maker should use. Frequency is as much dependent on process node as it is on the NPU design and will vary from NPU to NPU. For example, the same IP will produce different results when different frequencies are used. Consider a 54K MAC engine at 1GHz produces 108 TOPS, while the same 54K MAC engine at 1.25GHz yields 135 TOPS. Increasing the frequency results in more TOPS, but at the cost of disproportionally increased power consumption. In the case of chip-based NPUs, the maximum processing frequency will be fixed, while for IP-based NPUs (like Expedera’s) frequencies will depend on the actual silicon implementation. When comparing benchmark results from different vendors, it’s important to normalize for any differences in the frequency used for testing.
Neural Network(s) Employed as a Variant in TOPS/W
After normalizing for frequency, we next need to examine the Neural Network(s) used. Neural networks have a wide swath of characteristics.
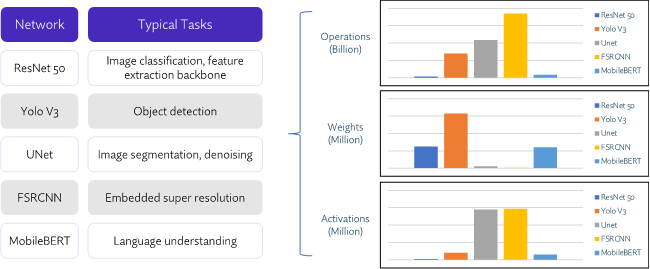
The figure above highlights how five commonly used neural networks can have huge differences in processing. For example, ResNet 50 has 27X fewer operations than Unet, but more than 12X the weights. Consequently, processing requirements (and performance) for each will vary. Run through the same engine, these two networks will produce different results. Run through competing engines, the two networks will likely produce greatly varied results that are not necessarily indicative of actual competitive performance. To get an accurate head-to-head comparison of AI engines, we need to run identical networks.
Precision as a Variant in TOPS/W
It is equally important to consider the precision of those networks. An engine running a neural network at an INT4 level of precision will only need to process half the data compared to an INT8 version of the same neural network, leading to a much-decreased processing load. Ideally, NPU providers will report data for the same level of precision for all layers of the network – whether for power or performance (or both). In practice, some engines will decrease precision in certain processing-intense layers to stay within power envelopes. While this approach is neither inherently correct nor incorrect, it can be confusing for benchmarking because an AI engine that lowers precision in one or more layers can give the appearance of processing advantages versus another engine that employs a higher level of precision throughout the network.
Sparsity and Pruning as a Variant in TOPS/W
The next question that needs to be asked is whether processing-saving techniques like sparsity or pruning are used. Both sparsity and pruning are generally accepted methods to reduce processing needs or lower the power consumption of an AI engine through the avoidance of calculations based on 0 values in multiplication equations or the removal of redundancies in the least important parts of models. Using these techniques can lead to significant PPA (performance, power, area) gains—some networks allow 30% sparsity or more with very small negative effects on network accuracy. If unreported in the assumptions of TOPS/W, the previous example would provide an artificial 30% performance advantage versus another NPU where 0 sparsity is used on the same network.
Process Node as a Variant in TOPS/W
Understanding the underlying conditions for the testing helps establish an equal playing field for comparing TOPS results for different NPUs. Ideally, benchmarking conditions can be configured or interpolated to closely match your application requirement. But you will likely need to take steps when comparing NPUs including the normalization of processing frequency, the use of an identical neural network(s) with identical precision, and the application (or not) of sparsity and pruning throughout.
We now need to consider the process node as it relates to power consumption. One of the major advantages of moving to smaller process nodes is smaller nodes generally require less power for the same action. For instance, an NPU in TSMC 5nm will likely consume about 25% less power than the same NPU in TSMC 7nm. This is true for both IP and chip-based NPUs. Because process node has a powerful influence on performance it must be considered when comparing benchmark data. It is important to ask an NPU supplier whether the power numbers are measured in actual silicon, extrapolated from actual silicon, or are based on simulation. If actual silicon was used, then the vendor should indicate which process node.
Memory Power Consumption as a Variant in TOPS/W
A hot topic within the AI industry is how to account for the power consumption of the memory in a TOPS/W conversation. Some AI providers do, while others do not. All AI engines require memory—some require huge amounts of memory compared to others. A reasonable strategy is to think about how much memory is optimal for your application and normalize reported results accordingly.
Utilization as a Variant in TOPS/W
As we can see, it is not easy to assess and compare the performance potential of an NPU. And still, there is one more factor that is often overlooked: processor utilization. Like all processors, NPUs are not 100% utilized. This means that for certain percentages of time, processors are idle while awaiting the next data set as that data shifts around in memory. While processors may have ‘sweet spots’ within their performance range where utilization is high, overall, this tends to vary wildly within the performance range. Having high utilization is a good thing because it minimizes idle time and stalls that can impede performance. At the same time, it reduces the power and area required. This is because, in principle, a processor running at 90% utilization can do the work of two comparable processors running at 45% utilization. Expedera calculates utilization as follows: Utilization = Total actual compute operations executed for NN inference / TOPS.
Finding the Right NPU for Your Application
It would certainly be easier if all NPU makers provided TOPS/W specifications in a standard manner or at least included all the underlying configuration information discussed above. To make evaluation easier for our customers, Expedera provides the detailed information below on how we benchmark our NPU to achieve 18 TOPS/W. If you’d like to explore whether our NPU is the right fit for your application, talk to us and we’d be happy to provide results specifically for your application workload.
