
We recently had a chance to speak with Brian Bailey over at Semiconductor Engineering. Brian had attended a keynote at DAC 2021 by Bill Dally, chief scientist at Nvidia on GPUs, Machine Learning, and EDA. Bill seemed to be making the bold claim that the GPU outperforms every other DLA solution on the market. As he explained, this is because new GPUs use software that makes model execution much more efficient such that the energy overhead of a single operation is just 16%. Bill argued that if the new specialized deep learning accelerators could at best achieve only 16% improvement, it’s not worth the tradeoff because a GPU offers much more flexibility. Brian posed the question: if this is correct, then why is the industry seeing such an influx of new AI chip/IP startups? Put another way, why does the industry need yet another deep learning accelerator?
The argument posited in Bill’s keynote is very processor-centric. The processor-centric approach that has been used for conventional software programs execution doesn’t work well for AI because of the massive amount of data movement required for neural network model execution. Consider, for example, as Mark Horowitz pointed out in his presentation, “Computing’s Energy Problem and What We Can Do About It,” the amount of energy needed for a 32bit SRAM read is 25x more than for an 8-bit multiply function. AI processing, particularly at the edge, is about minimizing data movement and managing memory bandwidth: it needs to be addressed at a system level, and not just as raw compute problem.
In our previous blog post, we talked about how existing AI architectures are highly inefficient. Because they tend to rely on traditional CPU-centric designs, their effective utilization—the time spent actually processing, rather than waiting for the next processing cycle—is very low. We challenged ourselves to test the hypothesis that the performance limitation of existing AI processors is due to fundamental inefficiencies in processing approaches. We’ll pick up from there…
We examined typical architectural approaches for neural network processing—the CPU-centric approach, which uses instructions as a work unit, and the Interpreter-centric approach, which uses a neural network layer as a work unit.
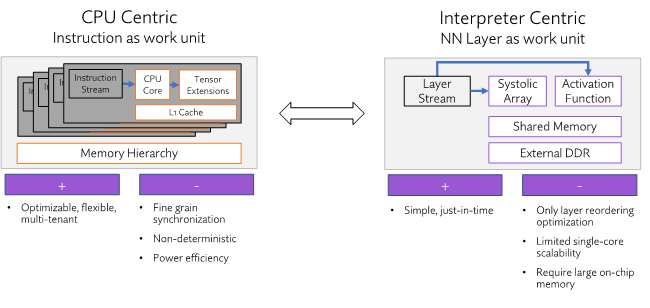
The CPU-centric approach is well known and understood, having been with us since the beginning of computing. It is optimizable, flexible, and allows multiple applications to coexist quite seamlessly. However, CPUs don’t have a notion of scheduling built in. This means any work must rely solely on synchronization primitives. The memory hierarchies in these systems are cache-based, which means they are not deterministic. Even a simple change like where a tensor is located can completely change the memory access pattern. And finally, because a layer needs to be broken up into multiple compute blocks and gathered back, they are limited in terms of power efficiency. This work unit, while very powerful, doesn’t allow for an optimized software/hardware utilization.
Now let’s look at the interpreter-centric approach. These are relatively simple implementations and due to their simplicity, they can do just-in-time compilation. But they’re limited—they can only perform layer reordering optimization, they have limited scalability, and require large amounts of expensive on-chip memory. This approach doesn’t bode well for AI acceleration.
The fundamental performance limitation within these two approaches is how neural networks are broken down into work units. Neither of the traditional approaches allows for optimum PPA (power, performance, area) customer deployments—rather, these approaches mainly try to apply existing architectures to a new problem, and neither do it very well.
To address this, we asked ourselves how we should (re)define those work units. This led to a packet-based approach.
Packets are an aggregate of work with a notion of dependencies and deterministic execution. A packet can be defined as a continuous fragment of neural network layer, which includes the entire context of execution: what layer type it is, what attributes it has (padding, stride, kernel size), what priority it is (high or low), as well what precision it can be executed on. For clarity: packet-based approaches, of course, are a commonly used approach in the networking world.
With packets as a work unit, we are able to simplify the AI software stack and increase performance of our DLA. The packet architecture allows us to right size the DLA early in the architecture phase. And it provides for seamless deployment in applications which range from persistent streaming applications to multiple jobs in high TOPS environments.
So, how does a packet-based DLA benefit system designers?
First, let’s look at actual packet execution. As we construct packets as work aggregates, we’ve created a work unit which can be fully utilized on our hardware. This is a key factor: our compiler examines a customer’s trained neural network, and then builds and schedules packets in a particular sequence in order to achieve very high throughput, or some other design goals. The close-knit integration of our hardware and software provides us a 70-90% utilization metric vs the 20-40% achieved by traditional approaches. And to note—we don’t require changes to our customers’ pre-existing neural network models to do this.
Scalability is also an advantage here. Packets are automatically distributed within the DLA amongst available resources. While we haven’t talked much about scalability yet (but will do so in subsequent blogs), the Expedera DLA can be scaled from sub-1 TOPS to 128 TOPS, to address applications from the most compute-light edge nodes all the way to high TOPS self-driving and data center use cases. And, our core scales without affecting memory footprint, and without negatively affecting utilization. The scalability ensures the “goldilocks’ AI engine for our customers—not too big, not too small. Finally, power is obviously a concern as well. Our packets are sequenced for low power at the cycle level, enabling power efficient implementations of our AI engine.
You may be a bit skeptical at this point. As W. Edwards Deming famously said, “In God we trust, all others must bring data”.
For the example below, we will use a YOLO v3 with an input image of 608 by 608 with a batch size of 2. This has 63 million total weights (largest layer of 4.3M) with 235 million total activations (largest layer of 24M), which executes 280 billion operations overall.
![]()
The graph above compares traditional layer-based approaches versus Expedera’s packet-based approach. To make sure we’re not cherry picking data, both approaches are optimized to utilize the minimum amount of memory and bandwidth.
What you can see is that the layer-based approach requires five times more external transfers than the packet-based approach. This means our packet-based approach enables higher throughput and lower system power while reducing the system BOM costs via lower external memory bandwidth requirements.
In terms of utilization, this required bandwidth is spread out over the execution of the entire neural network, which means that the utilization can be sustained throughout, and we can tolerate the latency variations that we see from external system fabric or from the DDR controller.
Circling back to the question we began with: Is the GPU really the optimal solution for every AI design? It is certainly true that the market has decided that the GPU is a good solution for many of today’s designs. Still, specialized accelerators can address one of the biggest problems with AI processing today: low utilization. Low utilization limits system throughput, leads to overdesign, and drives up system costs. Specialized accelerators can reduce processing overhead and improve resource utilization to deliver dramatic improvements. For example, with its packet-based architecture, Expedera’s DLA offers the following advantages:
- Improves resource utilization from the current ~30% to >90%
- Reduces the number of memory accesses required
- Reduces total memory size requirements
- Eliminates the need for off-chip memory for some applications
- Provides deterministic performance
- Runs trained models unchanged
- Reduces software complexity
Expedera’s customizable DLA IP offers higher performance per watt (18TOPS/watt). It enables lower power solutions and scales to very high performance using less power and area. A purpose-build DLA solution can reduce system hardware requirements, including memory, to lower BOM costs. Expedera’s co-design solution reduces overall design complexity, including a simpler software stack, to speed deployment and reduce risks.
Whew…so that’s a lot for today. We’ll be back soon with more discussions of our architecture, including a more in-depth look at our compiler, software stack, and many other things.
Have questions? We’d love to hear from you. Drop us a note here, and we will be in touch.