
我们最近有机会与 Semiconductor Engineering 的 Brian Bailey 进行了交谈。 Brian 参加了由英伟达首席科学家 Bill Dally 在 2021 年 DAC 上发表的关于 GPU、机器学习和 EDA 的主题演讲。 Bill 似乎大胆地宣称,GPU 的性能优于市场上所有其他 DLA 解决方案。 正如他所解释的,这是因为全新的 GPU 所使用的软件能使模型执行效率高得多,单次操作的能量开销仅为 16%。 Bill 认为,如果新的专业深度学习加速器最多能实现的改进仅达到 16% 而不能更低,那么就不值得权衡,因为 GPU 可以提供更大的灵活性。 Brian 提出了一个问题:如果这是正确的,那么为什么这个行业会有这么多新的 AI 芯片/IP 初创公司涌入? 换句话说,该行业为什么还需要另一个深度学习加速器?
在 Bill 的主题演讲中提出的论点尤其以处理器为中心。 用于传统软件程序执行的以处理器为中心的方法不太适合 AI,因为神经网络模型执行需要大量数据移动。 例如,正如 Mark Horowitz 在他的演讲《计算的能量问题和我们能做些什么》中指出的那样,32 位 SRAM 读取所需的能量是 8 位乘法函数所需能量的 25 倍。 AI 处理在于将数据移动和内存带宽管理降至最低水平,尤其是在边缘:这需要在系统级别解决,而不仅仅是一个原始计算问题。
在我们早期的博客文章中,我们谈到了现有的 AI 架构低效是多么低。 由于它们往往依赖于以 CPU 为中心的传统设计,因此有效利用率(实际用于处理的时间,而非等待下一个处理周期的时间)极低。 我们想要挑战一下自己,对这一假设进行了测试,即现有 AI 处理器的性能限制来源于处理方法根本上的低效。 我们从那里开始……
我们研究了神经网络处理的典型架构方法(以 CPU 为中心的方法,其使用指令作为工作单元)和以解释器为中心的方法(使用神经网络层作为工作单元)。
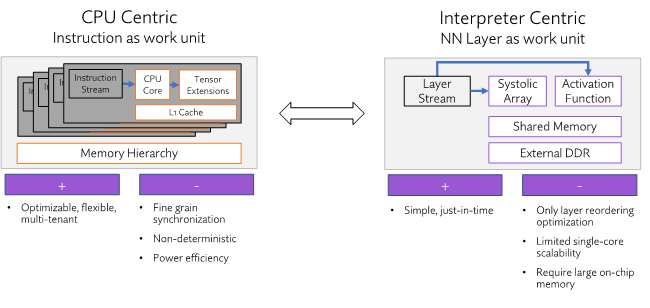
以 CPU 为中心的方法众所周知,也得到了广泛的了解,从计算时代开始就一直伴随着我们。 它灵活多变,可以进行优化,允许多个应用无缝共存。 然而,CPU 没有内置调度的概念。 这意味着,任何工作都必须完全依赖于同步原语。 这些系统中的内存层次结构是基于缓存的,这意味着它们不是确定的。 即使是简单的改变也可以完全改变内存访问模式,如张量的位置。 最后,由于一个层需要被分解成多个计算块并重新收集,它们的功耗效率会受到限制。 这个工作单元虽然功能强大,但无法实现优化的软件/硬件利用率。
现在,让我们看看以解释器为中心的方法。 它们是相对简单的实施,由于非常简洁,因此可以进行即时编译。 但它们会受到限制,只能执行层重新排序优化,可扩展性有限,并且需要大量昂贵的片上内存。 这种方法对 AI 加速来说不是个好兆头。
这两种方法的基本性能限制在于,如何将神经网络分解为工作单元。 这两种传统方法都无法实现最佳 PPA(功耗、性能、面积)客户部署;相反,这些方法主要尝试将现有的架构应用于新问题,而且都做得不好。
为了解决这个问题,我们问自己应该如何(重新)定义这些工作单元。 这就带来了基于数据包的方法。
数据包是工作的集合,具有依赖性和确定执行的概念。 数据包可以定义为神经网络层的连续片段,这包括整个执行环境:它是什么层类型,具有什么属性(填充、威胁、内核大小),优先级是什么(高或低),以及可以在什么精度上执行。 为清楚起见:基于数据包的方法当然是网络世界中常用的方法。
以数据包为工作单元,我们能够简化 AI 软件栈并提高 DLA 的性能。 数据包架构允许我们在架构阶段的早期适当调整 DLA 的大小。 对于从持久流应用到高 TOPS 环境中的多个作业等众多应用,它还为其无缝部署提供各种能力。
那么,基于数据包的 DLA 如何让系统设计人员受益?
首先,让我们看看实际的数据包执行情况。 随着我们将数据包构造为工作集合,我们创建了可在硬件上充分利用的工作单元。 这是一个关键因素:我们的编译器会检查客户训练好的神经网络,然后按照特定的顺序构建和调度数据包,以实现非常高的吞吐量或其他一些设计目标。 硬件和软件的紧密集成为我们提供 70 至 90% 的利用率指标,而传统方法的利用率为 20 至 40%。 需要注意的是,我们不需要更改客户预先存在的神经网络模型就可以做到这一点。
可扩展性也是一个优势。 数据包在 DLA 内的可用资源中自动分发。 虽然我们还没有太多地讨论可扩展性(但将在后续的博客中讨论),但艾伯德 DLA 可以从不足 1 TOPS 扩展到 128 TOPS,满足从最为轻量级计算的边缘节点到高 TOPS 自动驾驶和数据中心用例等应用的要求。 而且,我们的核心可在不影响内存占用的情况下进行扩展,也不会对利用率产生负面影响。 可扩展性确保了我们客户使用的“goldilocks”AI 引擎不会太大,也不会太小。 最后,功耗显然也是一个问题。 我们的数据包在循环级别进行排列以获得低功耗,实现了我们 AI 引擎的节能实施。
在这一点上,您可能会有点怀疑。 正如 W. Edwards Deming 所说,“我们相信的是,所有其他方面都必须带来数据”。
在下面的例子中,我们将使用一个 YOLO v3,其输入图像为 608×608,批量大小为 2。 它有 6300 万总权重(最大的一层为 430 万),总激活值为 2.35 亿次(最大的一层为 2400 万),总共执行 2800 亿次操作。
![]()
上图比较了基于层的传统方法和艾伯德基于数据包的方法。 为了确保我们不是只挑选有利数据,这两种方法都经过了优化,以利用最少的内存和带宽。
您可以看到,基于层的方法需要的外部传输为基于数据包的方法的五倍。 这意味着,我们基于数据包的方法能够实现更高的吞吐量和更低的系统功耗,同时通过减少外部内存带宽需求来降低系统 BOM 成本。
就利用率而言,所需的这一带宽分布在整个神经网络的执行中,这意味着利用率在整个过程中都会持续,我们可以容忍从外部系统结构或 DDR 控制器看到的延迟变化。
回到我们开始的问题:GPU 真的是每个 AI 设计的最佳解决方案吗? 当然,市场已经认定,对于当今的许多设计而言,GPU 都是优秀的解决方案。 不过,专门的加速器可以解决当今 AI 处理面临的最大问题之一:利用率低下。 低利用率会限制系统吞吐量,导致过度设计,并推高系统成本。 专门的加速器可以减少处理开销,提高资源利用率,从而实现显著的改进。 例如,凭借其基于数据包的架构,艾伯德的 DLA 具有以下优势:
- 将资源利用率从当前的约 30% 提高到 >90% 以上
- 减少所需的内存访问次数
- 降低总内存大小要求
- 消除某些应用对片外内存的需求
- 提供确定性能
- 无需更改即可运行训练好的模型
- 降低软件复杂性
艾伯德的可定制 DLA IP 提供更高的每瓦性能 (18 TOPS/W)。 它可以实现更低功耗的解决方案,并使用更少的功耗和面积扩展到极高的性能。 专门构建的 DLA 解决方案可以减少系统硬件需求,包括内存,从而降低 BOM 成本。 艾伯德的协同设计解决方案降低了总体设计复杂性,包括更简单的软件栈,从而加快部署并降低风险。
哇……今天就讲到这里了。 稍后,我们会回来详细介绍我们的架构,包括更深入地探讨我们的编译器、软件栈和许多其他东西。
有任何疑问? 我们很想听到您的消息。 在此处给我们留言,我们将会与您联系。